こんにちは、最近は記事を書くより *.instructions.md をいじってる時間のほうが長い気がするアーキテクトのやまぱんです 😅
エージェント界隈、毎週のように「新しいモデルが賢くなった」というニュースが流れてきますよね。でも実際に使っていると、賢さと同じくらい「どう包むか」で結果が変わると感じませんか。同じモデルでも、ツールの渡し方やコンテキストの管理次第で、できる仕事の量がまるで違ってくる。
その「どう包むか」を正面から定義したのが、LangChain の Vivek Trivedy さんによる記事 The Anatomy of an Agent Harness(2026/03/10)です。読んでいて「これ、自分が GitHub Copilot まわりでこねくり回してきたやつ、全部ここに名前がついてるな」と妙に腑に落ちたので、この記事ではその内容を日本語で整理しつつ、自分の Copilot カスタマイズ設定と Claude Code / Codex の harness を並べて読み直していきます。
Contents
TL;DR
- LangChain の記事によると、エージェントの正体は
Agent = Model + Harness。モデル以外のコード・設定・実行ロジックは全部「ハーネス(harness)」です。 - ハーネスの構成要素は、システムプロンプト・ツール / Skills / MCP・ファイルシステム・サンドボックス・オーケストレーション・Hooks の 6 系統くらいに分解できます。
- 面白いのは、これらが全部「モデル単体ではできないこと」から逆算して導かれている点。durable state、コード実行、最新知識、環境構築 — どれもモデルの外側で支える機能です。
- 私の GitHub Copilot 設定(
copilot-instructions.md、.instructions.md、SKILL.md、/memories/、カスタムエージェント)を並べてみたら、見事にこの 6 系統へマッピングできました。名前を知らずに harness を組んでいた、という感覚です。 - LangChain 曰く、同じ Opus 4.6 でも harness を変えるだけで Terminal Bench 2.0 のスコアが大きく動くとのこと。モデル選びと同じくらい「ハーネス設計」に伸びしろがあります。
ℹ️ この記事の事実ベースは LangChain の元記事です。私の体験談(Copilot 設定の話)と、元記事からの引用は分けて書くようにしています。「〜によると」とあるところは引用、「私の環境では」とあるところは実体験です。
そもそも「ハーネス」って何?
元記事のいちばんの主張はシンプルです。
Agent = Model + Harness
If you're not the model, you're the harness.
LangChain によると、ハーネスとは モデルそのものではない、すべてのコード・設定・実行ロジック のこと。生のモデルはエージェントではなく、ハーネスが state、ツール実行、フィードバックループ、強制可能な制約を与えて初めてエージェントになる、という整理です。
この関係を一枚にすると、こんなイメージです。モデルが「知能」で、ハーネスがその知能を「仕事に変える仕組み」。足し算の右側が全部ハーネスだと思うと分かりやすいです。

エージェント = モデル + ハーネス。モデルでない部分はすべてハーネスに含まれる
具体的にハーネスに含まれるものとして、元記事は次を挙げています。
- システムプロンプト
- ツール、Skills、MCP とその説明文(description)
- バンドルされたインフラ(ファイルシステム、サンドボックス、ブラウザ)
- オーケストレーションロジック(サブエージェントの起動、ハンドオフ、モデルルーティング)
- 決定論的な実行のための Hooks / ミドルウェア(compaction、継続、lint チェック)
この切り方が個人的にしっくりきました。「賢さ=モデル」「賢さを仕事にする仕組み=ハーネス」と分けると、自分がどこをいじっているのかが見えやすくなります。私が普段触っているのは、ほぼ 100% ハーネス側でした。
なぜハーネスがいるのか - モデルの素の限界から
元記事は「モデルの視点」から harness の必要性を導きます。モデルは結局、テキスト・画像・音声・動画を入力に取り、テキストを出力するだけ。素の状態だと次のことができません(LangChain による整理)。
- 対話をまたいで durable な state を保つ
- コードを実行する
- リアルタイムの知識にアクセスする
- 環境を整えてパッケージを入れ、作業を完了させる
これらは全部ハーネス側の機能だ、というのが論旨です。たとえば「チャットする」という体験ひとつ取っても、モデルを while ループで包んで過去メッセージを追跡し、新しい発言を追記している。私たちはすでにハーネスを使っているわけです。
元記事はこのあと「ほしいエージェントの挙動 → それを実現する harness 設計」というパターンで構成要素を一つずつ導いていきます。この逆算の流れが分かりやすかったので、以下も同じ順でたどります。
構成要素を分解する
ここからは、元記事が挙げる構成要素を順番に見ていきます。先に全体像を置いておくと、ハーネスはざっくり次の 6 系統に分けられます。緑が土台のプリミティブ、紫がその上で効いてくる応用、という色分けで眺めてみてください。
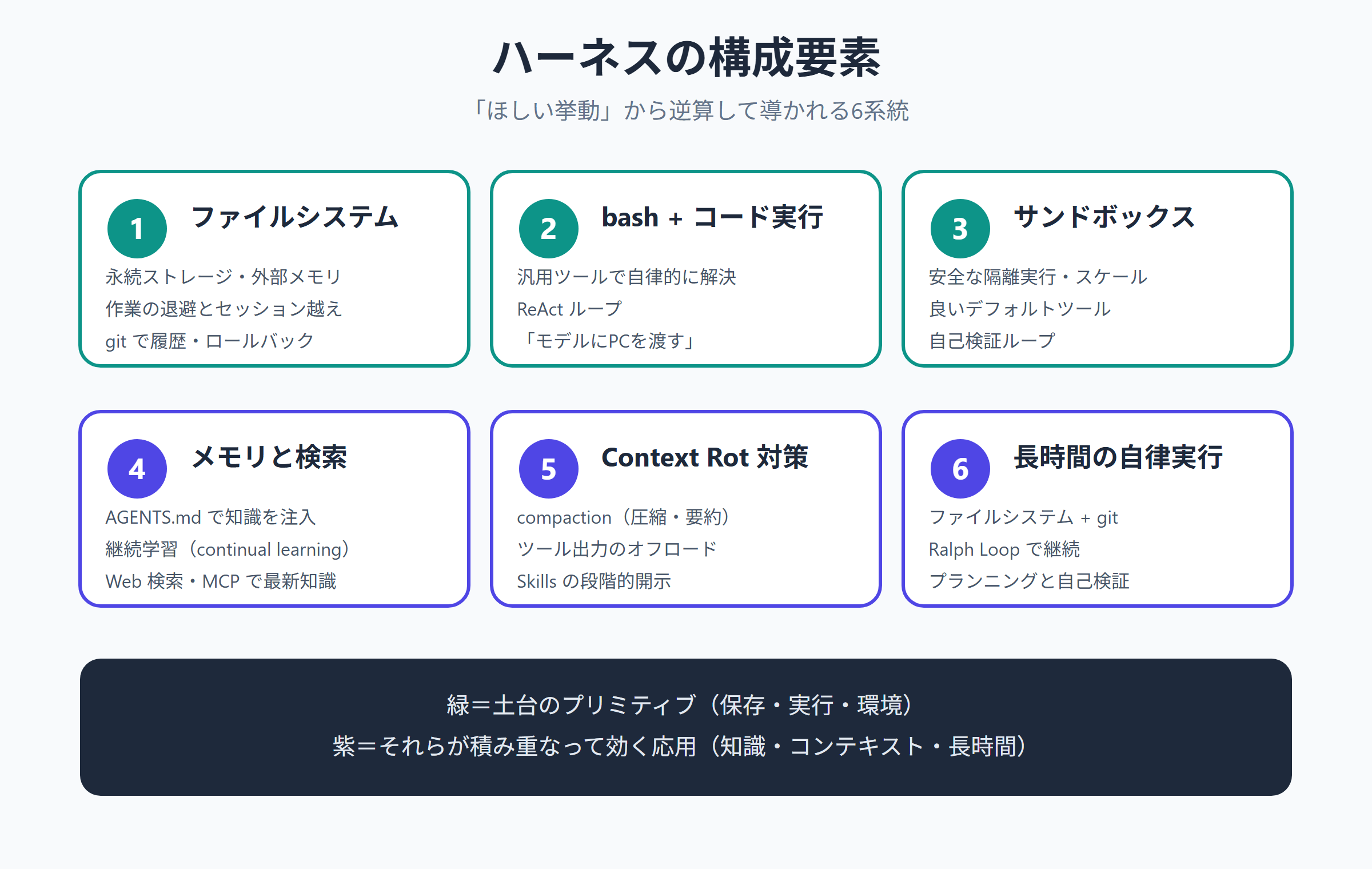
ハーネスの構成要素。緑=土台のプリミティブ(保存・実行・環境)、紫=それらが積み重なって効く応用
ファイルシステム - 一番土台になるプリミティブ
LangChain はファイルシステムを「もっとも基礎的な harness プリミティブ」と位置づけています。理由として挙げられているのは次のあたりです。
- エージェントがデータ・コード・ドキュメントを読むワークスペースになる
- コンテキストに乗り切らない情報を、ファイルに退避しながら少しずつ進められる
- 複数のエージェントや人間がファイルを介して協調できる(Agent Teams 的な構成)
さらに Git を足すと、作業の追跡・ロールバック・実験のブランチ分岐ができる、と。
私の体感とも一致します。Copilot に長めの作業を任せるとき、結局いちばん効くのは「途中結果をファイルに書かせる」ことでした。コンテキストに全部抱えさせると後半でだれてくるので、tmp/ に中間 JSON を吐かせて、必要なときだけ読み直させる。これがファイルシステムを「外部メモリ」として使う、という話そのものでした。
bash + コード実行 - 汎用ツールとしての強さ
次に LangChain が挙げるのが「汎用ツールとしての bash」です。今のエージェント実行の主流は ReAct ループ(推論 → ツール呼び出し → 結果観測 → 繰り返し)。でもハーネスは、ロジックを持つツールしか実行できない。ありとあらゆる操作にツールを用意するより、bash のような汎用ツールを 1 個渡すほうが筋がいい、という主張です。
Bash + code exec is a big step towards giving models a computer and letting them figure out the rest autonomously.
「モデルにコンピュータを渡して、あとは自分でなんとかさせる」という表現が好きです。私も、専用ツールを作り込むより、ターミナル(私の環境では PowerShell)を渡して「必要なスクリプトはその場で書いて」とお願いするほうが、結果的に詰まりにくいと感じています。決まった操作を 2 回以上やらせるなら小さなスクリプトに昇格させる、という運用も、この延長線上にありました。
サンドボックスと検証ツール - 安全に動いて、結果を確かめる
コードを実行できるようにすると、今度は「どこで動かすか」が問題になります。ローカルでエージェント生成コードをそのまま走らせるのはリスクがあるし、スケールもしない。そこでサンドボックスです。
LangChain が挙げる利点は、安全な隔離実行、コマンドの allow-list、ネットワーク隔離、そしてオンデマンドに作って・並列に展開して・終わったら捨てるというスケール面。さらに「良い環境には良いデフォルトツールが入っている」として、言語ランタイム、git CLI、テスト、ブラウザ(vercel-labs/agent-browser)を事前に入れておく話が続きます。
ブラウザ・ログ・スクリーンショット・テストランナーが揃うと、エージェントは「コードを書く → テストを回す → ログを見る → 直す」という自己検証ループを回せる。ここは私も日々お世話になっていて、Copilot に何か直させたあとは必ずエラーチェックを走らせて、失敗したら本人に投げ返す運用をしています。検証ループがあると、結果の確からしさが一段上がります。
メモリと検索 - 学習し続けるための仕組み
モデルは重みと今のコンテキストにある知識しか持ちません。重みを書き換えられない以上、「知識を足す」唯一の方法はコンテキストへの注入です。
ここでも主役はファイルシステム。LangChain は AGENTS.md のようなメモリファイル標準を挙げ、エージェント起動時にコンテキストへ注入され、更新されればまた読み込まれる、これは一種の継続学習(continual learning)だ、と説明しています。知識カットオフの先(新しいライブラリのバージョンなど)には、Web 検索や Context7 のような MCP ツールで届く、と。
私の環境だと、ここが /memories/(user / session / repo の 3 スコープ)と Agents.md に対応していました。よく踏むハマりどころや、このリポジトリ固有のビルドコマンドをメモファイルに書いておくと、次のセッションでそれが効いてくる。まさに「セッションをまたいで知識を持ち越す」挙動で、最初に読んだときは「あ、これメモリ機能のことだ」と一人で納得していました。
コンテキスト腐敗(Context Rot)との戦い
個人的にいちばん刺さったのがこの章です。LangChain は Context Rot(コンテキストが埋まるほどモデルの推論・タスク遂行が悪くなる現象)を挙げ、ハーネスの今の主な役目は「良いコンテキストエンジニアリングの配送機構」だと言い切ります。対策として 3 つ。
- Compaction: コンテキストが埋まりかけたら、既存の内容を賢く退避・要約して、エージェントが作業を続けられるようにする。
- ツール呼び出しのオフロード: 大きなツール出力は、先頭と末尾のトークンを一定数残して、全体はファイルに退避。必要なときだけ読み戻す。
- Skills: 起動時に大量のツールや MCP がコンテキストへ載って性能が落ちる問題を、progressive disclosure(段階的開示)で解く。最初は説明文(front-matter)だけ読み込み、必要になったら本体を開く。
図にすると、3 つの対策はそれぞれ役割が違うのが見えてきます。圧縮するのか、退避するのか、そもそも最初から載せないのか、というアプローチの違いです。

Context Rot への3つの対策。圧縮・退避・段階的開示で、埋まりがちなコンテキストを健全に保つ
この 3 つ、どれも自分の環境で見覚えがありました。Copilot Chat は会話履歴を自動で圧縮してくれるし、大きなツール出力は途中で畳まれる。Skills も、最初は名前と説明だけがロードされていて、タスクに合致したときに本体が開く作りです。「なんでこういう作りなんだろう」と思っていた挙動が、Context Rot 対策という一本の理屈で説明できたのは収穫でした。
長時間の自律実行
最後は長時間タスクです。今のモデルは early stopping(途中でやめてしまう)、複雑な問題の分解が苦手、複数コンテキストウィンドウをまたぐと一貫性が崩れる、といった弱点を抱えている。ここまでのプリミティブが効いてくる場面だ、と LangChain は整理します。
- ファイルシステム + git で、セッションをまたいで作業と履歴を追跡する
- Ralph Loop(ghuntley.com/loop)で作業を継続させる。Hook がモデルの終了しようとする動きを横取りして、元のプロンプトをクリーンなコンテキストに再注入し、完了ゴールに向けて作業を続けさせるパターン。各反復は新しいコンテキストで始まり、前の反復の状態はファイルから読む
- プランニングと自己検証 で軌道を保つ。ゴールを手順に分解し、各ステップ後に Hook がテストを回して、失敗したらエラーを添えてモデルに戻す
私の環境で言うと、サブエージェントへの委譲、TODO リストでの計画管理、ステップごとのエラーチェックが、ちょうどこの章のプリミティブに当たります。長い作業ほど、賢さより「状態を落とさず続ける仕組み」がものを言う、というのは実感として強くありました。
自分の Copilot 設定を「ハーネス」として読み直す
ここまでで気づいたのは、私が GitHub Copilot まわりでこねくり回してきたものが、ほぼそのまま LangChain の harness 構成要素に対応していたことです。左にハーネスの構成要素、右に私の Copilot 設定を並べると、対応関係がそのまま線でつながります。

左:ハーネスの構成要素/右:私の Copilot 設定での対応物。名前を知らずに harness を組んでいた、という感覚
表にすると、こんな感じでした。
| LangChain の harness 構成要素 | 私の Copilot 設定での対応物 |
|---|---|
| システムプロンプト | copilot-instructions.md、*.instructions.md(applyTo で対象ファイルを限定) |
| ツール / Skills / MCP | SKILL.md で定義した Skills、各種 MCP サーバ |
| ファイルシステム / メモリ | /memories/(user / session / repo)、Agents.md |
| bash / コード実行 | ターミナルツール(PowerShell) |
| コンテキスト腐敗対策 | 会話の自動圧縮、Skills の段階的開示、ツール出力のオフロード |
| オーケストレーション | カスタムエージェント(役割分担)、サブエージェント委譲、モデルルーティング |
つまり、私がやっていた「instructions を整理する」「Skill に作業手順を切り出す」「メモリにハマりどころを書く」といった作業は、全部ハーネスエンジニアリングだったわけです。名前を知らずにやっていたものに名前がつくと、次に何を足せばいいかが見えやすくなりますね。
たとえば「instructions が増えすぎて毎回全部ロードされると重い」という悩みは、まさに Context Rot。だから applyTo でファイルを限定したり、常時ロードする内容を短く保ったり、詳細は Skill 側に逃がしたりしている。これらは LangChain の言う progressive disclosure の手作り版でした。
ハーネスとモデル学習のカップリング
元記事の後半、ここが地味に重要だと感じました。LangChain によると、Claude Code や Codex のような今のエージェント製品は、モデルとハーネスをループに入れた状態で post-training されている とのこと。ハーネス設計者が「ここはネイティブに得意であってほしい」と考える操作 — ファイル操作、bash 実行、プランニング、サブエージェントでの並列化 — をモデルが得意になるように学習させている、という話です。
これがフィードバックループを生みます。便利なプリミティブが見つかる → ハーネスに足す → 次世代モデルの学習に使う。サイクルが回るほど、モデルは「自分が学習したハーネスの中で」強くなる。
副作用として、過学習(overfitting)も起きる。元記事は Codex-5.3 のプロンプトガイドにある apply_patch のツールロジックを例に、「本当に賢いモデルならパッチ方式の切り替えくらい簡単なはずなのに、ハーネスごと学習すると特定の方式に過剰適合する」と指摘しています。
そして示唆的なのが Terminal Bench 2.0 のリーダーボード。LangChain によると、Claude Code 上の Opus 4.6 は、他のハーネス上の Opus 4.6 よりスコアがかなり低いとのこと。LangChain 自身も、自社コーディングエージェントを ハーネスだけ変えて Terminal Bench 2.0 で Top 30 から Top 5 に上げた と書いています。
ここは比較記事的にも面白いポイントでした。どのハーネスも一長一短で、優劣を単純に言うものではないけれど、「モデルが post-train されたハーネスが、そのタスクにとって最良とは限らない」という観点は、ツール選びのときに頭に置いておきたいところです。同じモデルでも器で結果が変わる、というのを数字で見せられると説得力がありますね。
これからのハーネス
最後に、LangChain の見通しを引いておきます。モデルが賢くなるにつれて、今ハーネスにある機能の一部はモデル側へ吸収されていく。プランニング、自己検証、長時間の一貫性は、いずれネイティブに得意になり、コンテキスト注入が減っていくだろう、と。
ただ、それでもハーネスエンジニアリングは価値を持ち続ける、というのが結論です。プロンプトエンジニアリングが今も有効なのと同じで、よく設定された環境・適切なツール・durable な state・検証ループは、ベースの賢さに関係なくどんなモデルも効率的にする。元記事の締めの一文がきれいでした。
The model contains the intelligence and the harness is the system that makes that intelligence useful.
LangChain が挙げている未解決の研究テーマも刺激的です。
- 共有コードベース上で数百のエージェントを並列にオーケストレーションする
- エージェントが自分のトレースを分析して、ハーネスレベルの失敗モードを自分で見つけて直す
- 事前設定ではなく、タスクごとに必要なツールとコンテキストをジャストインタイムで動的に組み立てるハーネス
3 つ目は、自分の手作業(タスクに応じて instructions や Skill を出し入れする)を自動化した姿に見えて、いちばんワクワクしました。LangChain はこの領域の研究を deepagents というライブラリに反映しているそうなので、ここは別途追いかけてみるつもりです。
参考
- The Anatomy of an Agent Harness - LangChain Blog(この記事の起点。Vivek Trivedy、2026/03/10)
- Context Rot - Chroma Research(コンテキストが埋まるほど性能が落ちる現象)
- The Ralph Loop - ghuntley.com(終了を横取りして作業を継続させるパターン)
- AGENTS.md(エージェント向けメモリファイル標準)
- Terminal Bench 2.0 Leaderboard(ハーネス差が出るベンチマーク)
- deepagents - LangChain Docs(LangChain のハーネス構築ライブラリ)
まとめ
Agent = Model + Harness という分け方は、エージェントを触っている人ほど効くフレームだと思います。私の場合、賢いモデルが出るたびに「すごい」と言いつつ、実際に手を入れていたのはほぼハーネス側でした。instructions、Skills、メモリ、カスタムエージェント — 名前を知らずに harness を組んでいたんだな、と元記事を読んで腹落ちした次第です。
これから自分の Copilot 設定をいじるときは、「これはどの harness 構成要素を強化しているのか」を意識してみようと思います。Context Rot 対策なのか、長時間実行の安定化なのか、メモリの継続学習なのか。目的に名前がつくと、足すべきものと削るべきものの判断が速くなりそうです。
エージェントのカスタマイズをやっている方は、ぜひ一度、自分の設定を harness の 6 系統に並べ直してみてください。私みたいに「あ、これ全部ハーネスだったのか」と気づけて、ちょっと楽しいですよ~! 🎉
メタ要約案(120-160 文字): LangChain の「The Anatomy of an Agent Harness」を起点に、エージェント = モデル + ハーネスという見方を分解。ファイルシステム・bash・サンドボックス・メモリ・コンテキスト腐敗対策・長時間実行までを、自分の GitHub Copilot カスタマイズ設定と Claude Code / Codex の harness に並べて読み直した記録です。